CameraCtrl: Enabling Camera Control for Video
Diffusion Models
[arXiv Report] [Code] [BibTeX] [HF Demo]

[arXiv Report] [Code] [BibTeX] [HF Demo]
Abstract
Controllability plays a crucial role in video generation, as it allows users to create and edit content more precisely. Existing models, however, lack control of camera pose. To alleviate this issue, we introduce CameraCtrl, enabling accurate camera pose control for video diffusion models. Our approach explores effective camera trajectory parameterization along with a plug-and-play camera pose control module that is trained on top of a video diffusion model, leaving other modules of the base model untouched. Moreover, a comprehensive study on the effect of various training datasets is conducted, suggesting that videos with diverse camera distributions and similar appearance to the base model indeed enhance controllability and generalization. Experimental results demonstrate the effectiveness of CameraCtrl in achieving precise camera control with different video generation models, marking a step forward in the pursuit of dynamic and customized video storytelling from textual and camera pose inputs.
Demo Video
Framework
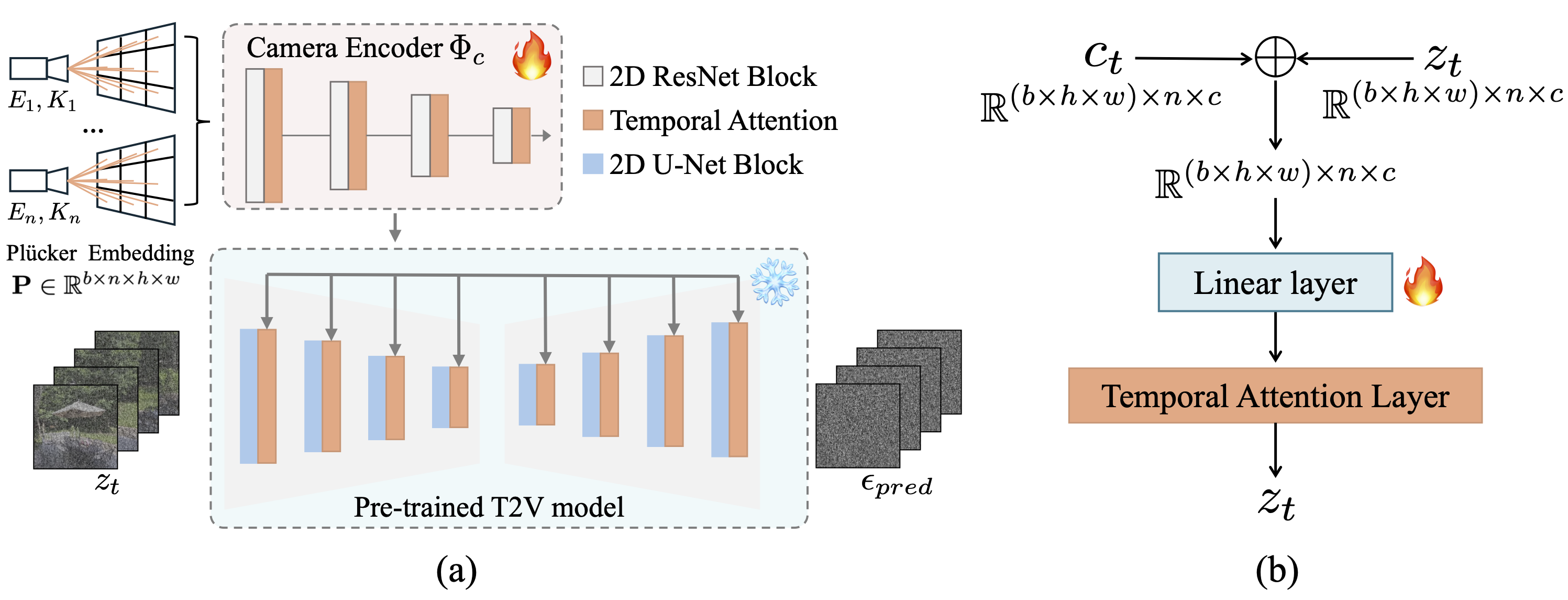
Framework of CameraCtrl (a) Given a pre-trained video diffusion model, CameraCtrl trains a camera encoder on it, which takes the Plücker embedding as input and outputs multi-scale camera representations. These features are then integrated into the temporal attention layers of the U-Net at their respective scales to control the video generation process. (b) Details of the camera injection process. The camera features and the latent features are first combined through the element-wise addition. A learnable linear layer is adopted to further fuse two representations which are then fed into the first temporal attention layer of each temporal block.
Visualization Results
CameraCtrl for general text-to-video generation
Same text prompt + Different camera trajectories
CameraCtrl for personalized text-to-video generation
CameraCtrl for image-to-video generation
Integration CameraCtrl with other video control methods
BibTeX
@misc{he2024cameractrl,
title={CameraCtrl: Enabling Camera Control for Text-to-Video Generation},
author={Hao He and Yinghao Xu and Yuwei Guo and Gordon Wetzstein and Bo Dai and Hongsheng Li and Ceyuan Yang},
year={2024},
eprint={2404.02101},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
We borrow the source code of this project page from DreamBooth.